
Python is often the first language that comes to mind when we talk about scraping data from websites. Its powerful libraries and easy syntax have made it a go-to choice for many. But what if I told you there’s a whole world of web scraping beyond Python?
In this article, we’ll explore alternative methods for scraping websites that don’t rely on Python. You might be surprised to learn that you don’t always need to write Python code to gather data from the web. Whether you’re new to coding or a seasoned pro, we’ll walk you through tools and techniques that make web scraping accessible to everyone.
First, let’s revisit the basics. At its core, web scraping is the process of extracting data from websites or web applications. Developers and data enthusiasts use this technique to gather information for analysis, research, or automation.
To showcase the versatility of web scraping, we’ll demonstrate how to extract data using various programming languages. For this blog, we’ll use Scrape It as our example website.
Our task is straightforward: we’ll fetch the HTML content of the Scrape It website and extract the text within the <title> tag. It’s a simple yet powerful example that highlights the accessibility and practicality of web scraping.
So our goal is to get this text “Scrape IT – Wij scrapen data voor jou” from the website
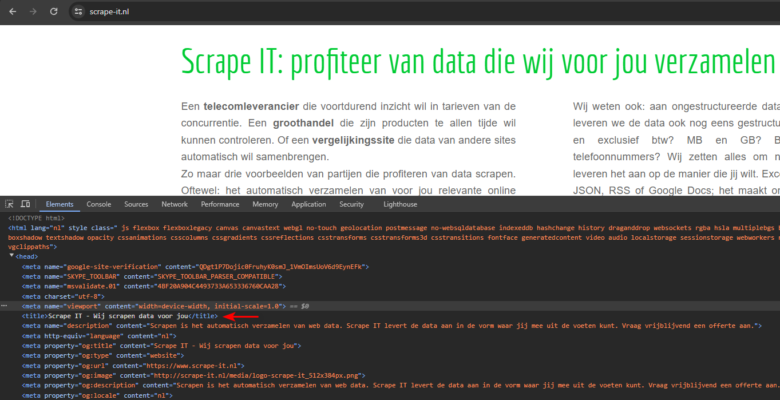
To get the text we want from the website, we’ll do two things:
- Get the website code: First, we’ll grab the website’s code. It’s like getting a book to find the information we need.
- Find the title: Next, we’ll look through the code to find the title. It’s like searching for a specific word in a book.
Alright, let’s kick things off with a language that holds a special place in many developers’ hearts – C. If you’re like me, C was probably one of the first languages you learned, and it still has that nostalgic charm.
Web scraping using C programming language.
Code:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_HTML_SIZE 100000 // Maximum size of HTML content to store
int main() {
char html[MAX_HTML_SIZE]; // Buffer to store the HTML content
FILE *curl_output; // File pointer to capture curl output
char *title_start, *title_end; // Pointers to start and end of <title> tag
// Run curl command and capture output
curl_output = popen("curl https://scrape-it.nl/", "r");
if (curl_output == NULL) {
printf("Failed to run curl command.n");
return 1;
}
// Read the output of curl into html buffer
fread(html, sizeof(char), MAX_HTML_SIZE, curl_output);
// Close the file pointer
pclose(curl_output);
// Find the start of first <title> tag
title_start = strstr(html, "<title>");
if (title_start == NULL) {
printf("No <title> tag found.n");
return 1;
}
// Move pointer to start of content within <title> tags
title_start += 7; // Move to the position after "<title>"
// Find the end of first <title> tag
title_end = strstr(title_start, "</title>");
if (title_end == NULL) {
printf("Invalid <title> tag.n");
return 1;
}
// Null-terminate the content within <title> tags
*title_end = '�';
// Print the content within first <title> tag
printf("Content within <title> tag: %sn", title_start);
return 0;
}
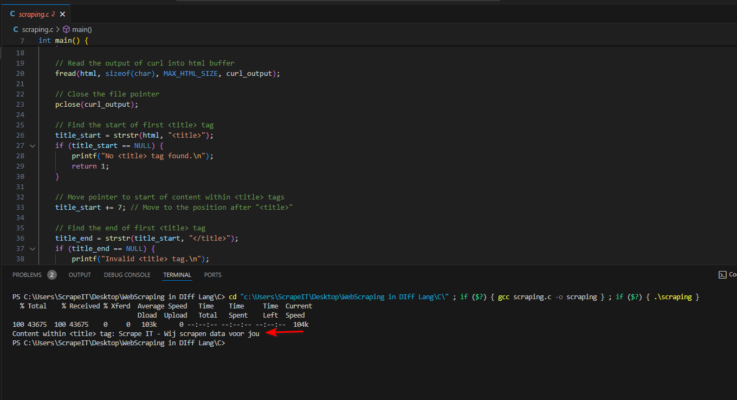
This code fetches the title of a Scrape IT website, It uses a tool called curl to get the HTML content of the website. Then, it searches for the title within the HTML code and prints it out.
Output:
Web scraping using C #
Code:
using System;
using HtmlAgilityPack;
namespace ScrapeItScrapingCSharp
{
internal class Program
{
static void Main(string[] args)
{
// Create HtmlWeb instance
HtmlWeb web = new HtmlWeb();
// Load website
HtmlDocument doc = web.Load("https://scrape-it.nl/");
// Get title node
HtmlNode titleNode = doc.DocumentNode.SelectSingleNode("//title");
// Check if title node exists
if (titleNode != null)
{
// Print title text
Console.WriteLine("Content within <title> tag: " + titleNode.InnerText);
}
else
{
// Print error message if title node is not found
Console.WriteLine("No <title> tag found.");
}
}
}
}
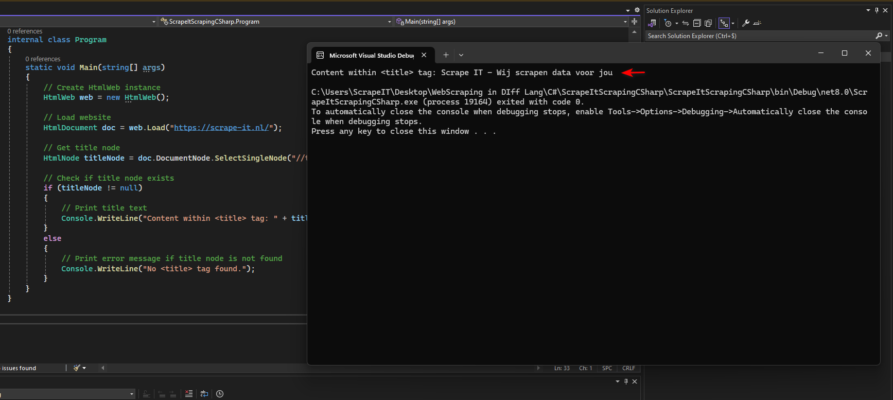
This code fetches the HTML content of a website and utilizes the HtmlAgilityPack library in C#. With its capabilities, we easily target the <title> element using XPath and extract its text. This straightforward approach simplifies HTML parsing, making it effortless to fetch specific elements from the website.
Output:
Web scraping using Java
Code:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class Main {
public static void main(String[] args) {
// URL of the website to scrape
String url = "https://scrape-it.nl/";
try {
// Connect to the website and get the HTML document
Document doc = Jsoup.connect(url).get();
// Get the title element
Element titleElement = doc.select("title").first();
// Check if the title element exists
if (titleElement != null) {
// Print the title text
System.out.println("Content within <title> tag: " + titleElement.text());
} else {
// Print error message if title element is not found
System.out.println("No <title> tag found.");
}
} catch (IOException e) {
// Print error message if connection fails
System.out.println("Failed to fetch HTML content: " + e.getMessage());
}
}
}
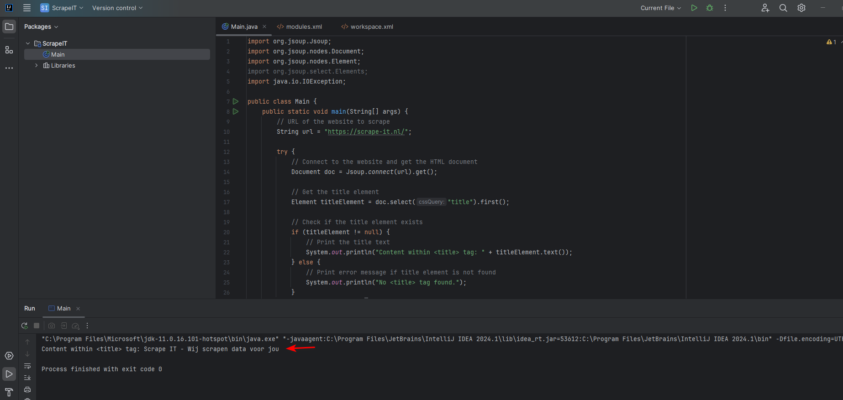
This Java code fetches the HTML content of a website and employs the Jsoup library. Jsoup facilitates HTML parsing and navigation, allowing us to easily target the <title> element using CSS selector syntax. By retrieving the text of the <title> element, we obtain the title of the website.
Output:
Web scraping using Javascript
Code:
// URL of the website to scrape
const url = 'https://scrape-it.nl/';
// Fetch HTML content
fetch(url)
.then(response => response.text())
.then(html => {
// Parse HTML content
const parser = new DOMParser();
const doc = parser.parseFromString(html, 'text/html');
// Get the title element
const titleElement = doc.querySelector('title');
// Check if the title element exists
if (titleElement) {
// Print the title text
console.log(`Content within <title> tag: ${titleElement.textContent}`);
} else {
// Print error message if title element is not found
console.log('No <title> tag found.');
}
})
.catch(error => {
// Print error message if fetching fails
console.error(`Failed to fetch HTML content: ${error}`);
});
This JavaScript code fetches the HTML content of a website using the native fetch API. By leveraging the DOMParser interface, we parse the HTML content and navigate through the document to target the <title> element. Once the <title> element is identified, we extract its text to obtain the title of the website
Output:
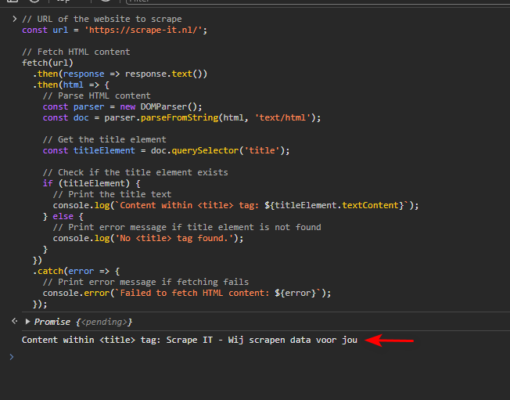
Web scraping using NodeJS
Code:
const axios = require('axios');
const cheerio = require('cheerio');
// URL of the website to scrape
const url = 'https://scrape-it.nl/';
// Fetch HTML content
axios.get(url)
.then(response => {
// Load HTML content into cheerio
const $ = cheerio.load(response.data);
// Get the title element
const titleElement = $('title');
// Check if the title element exists
if (titleElement) {
// Print the title text
console.log(`Content within <title> tag: ${titleElement.text()}`);
} else {
// Print error message if title element is not found
console.log('No <title> tag found.');
}
})
.catch(error => {
// Print error message if fetching fails
console.error(`Failed to fetch HTML content: ${error}`);
});
This Node.js code fetches the HTML content of a website using the axios library, a popular HTTP client for Node.js. Utilizing the cheerio library, we load the HTML content into a virtual DOM and use jQuery-like syntax to traverse and manipulate the HTML structure. By targeting the <title> element, we extract its text to retrieve the title of the website
Output:
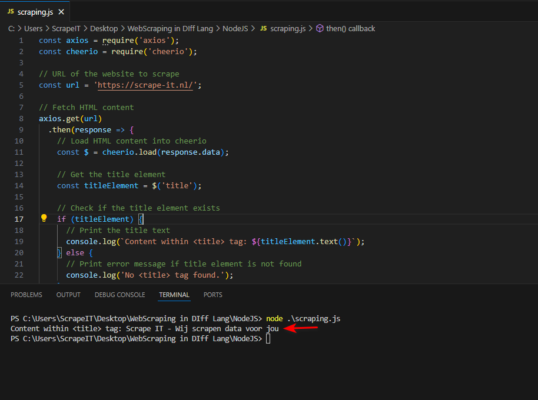
What if we aim to perform web scraping using the first programming language ever created?
I asked Google what the first programming language is, and its answer was Fortran.
Web scraping using Fortran
Code:
PROGRAM ReadFile
CHARACTER(100) :: line
INTEGER :: title_start, title_end
CHARACTER(100) :: title
! fetch the page
CALL SYSTEM('curl -s https://scrape-it.nl/ > html_content.txt')
! Open the input file
OPEN(UNIT=10, FILE='html_content.txt', STATUS='OLD', ACTION='READ')
! Read each line of the file
DO
READ(10, '(A)', END=20) line
! Check if the line contains the <title> tag
title_start = INDEX(line, '<title>')
IF (title_start > 0) THEN
! Extract the title text
title_end = INDEX(line(title_start:), '</title>') + title_start - 1
title = line(title_start + LEN('<title>'):title_end - 1)
PRINT *, 'Title:', title
END IF
END DO
20 CONTINUE
! Close the input file
CLOSE(10)
! Prompt for user input to prevent immediate exit
PRINT *, 'Press Enter to exit...'
READ(*, *)
END PROGRAM ReadFile
This Fortran code fetches the HTML content of a website using the curl command, then opens the saved file (html_content.txt) to read its content. It reads each line of the file, searching for the <title> tag. If found, it extracts the text between <title> and </title> and prints it
Output:
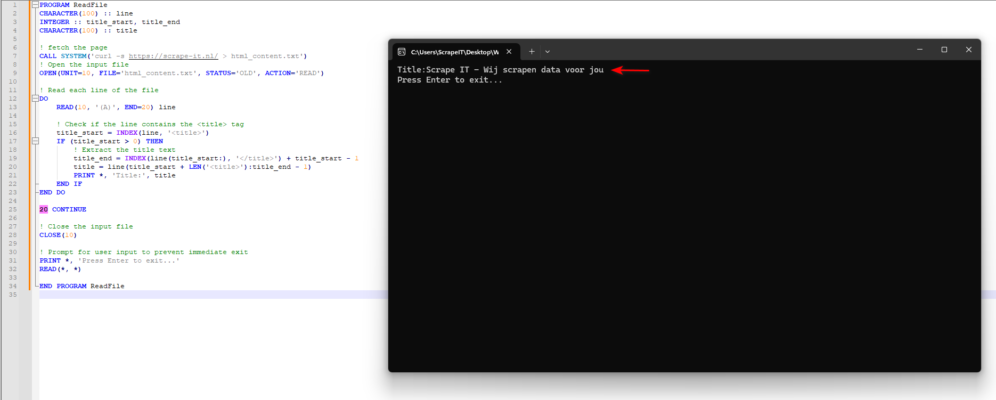
Concluding our exploration, we’ve covered the essentials of web scraping in this article. Think of it like choosing tools for a project—whether you prefer Python, C#, Java, or even Fortran, it’s about what suits your style. And hey, I’m not against Python—it’s still fun to code with Python too! But remember, web scraping isn’t dependent on any specific language. So, pick your favorite, dive in, and start uncovering the treasures hidden within the web!