
Python is vaak de eerste programmeertaal die in je opkomt als we het hebben over het scrapen van gegevens van websites. Dankzij de krachtige bibliotheken en eenvoudige syntaxis is het voor velen de eerste keuze. Maar wat als ik je vertel dat er een hele wereld van web scraping bestaat naast Python?
In dit artikel verkennen we alternatieve methoden voor het scrapen van websites die niet afhankelijk zijn van Python. Het zal je misschien verbazen dat je niet altijd Python-code hoeft te schrijven om gegevens van het web te verzamelen. Of je nu net begint met coderen of een doorgewinterde pro bent, we nemen je mee door tools en technieken die web scraping toegankelijk maken voor iedereen.
Laten we eerst even teruggaan naar de basis. In wezen is web scraping het proces waarbij gegevens van websites of webapplicaties worden gehaald. Ontwikkelaars en dataliefhebbers gebruiken deze techniek om informatie te verzamelen voor analyse, onderzoek of automatisering.
Om de veelzijdigheid van web scraping te laten zien, laten we zien hoe je gegevens kunt extraheren met behulp van verschillende programmeertalen. Voor deze blog gebruiken we Scrape IT als onze voorbeeldwebsite.
Onze taak is eenvoudig: we halen de HTML-inhoud van de Scrape IT website en halen de tekst uit de <title> tag. Het is een eenvoudig maar krachtig voorbeeld dat de toegankelijkheid en bruikbaarheid van web scraping benadrukt.
Dus ons doel is om deze tekst ”Scrape IT – Wij scrapen data voor jou“ van de website te halen
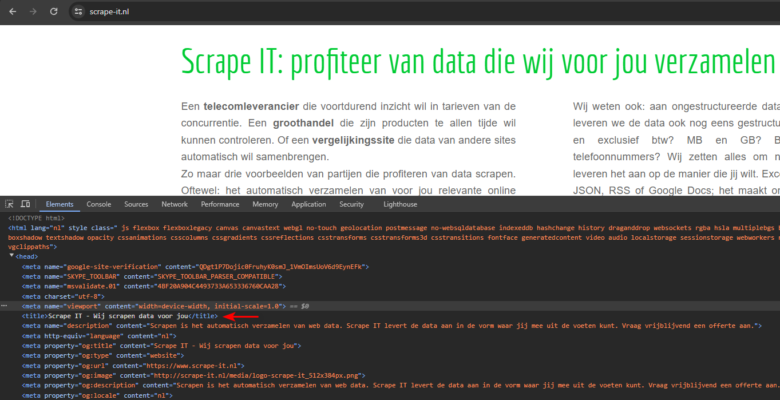
Om de tekst die we willen van de website te krijgen, doen we twee dingen:
- De websitecode ophalen: Eerst pakken we de code van de website. Het is alsof we een boek pakken om de informatie te vinden die we nodig hebben.
- Zoek de titel: Vervolgens zoeken we in de code naar de titel. Het is net als zoeken naar een specifiek woord in een boek.
Goed, laten we beginnen met een taal die een speciaal plekje heeft in het hart van veel ontwikkelaars - C. Als je op mij lijkt, was C waarschijnlijk een van de eerste talen die je leerde en het heeft nog steeds die nostalgische charme.
Scrapen van het web met de programmeertaal C.
Code:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_HTML_SIZE 100000 // Maximum size of HTML content to store
int main() {
char html[MAX_HTML_SIZE]; // Buffer to store the HTML content
FILE *curl_output; // File pointer to capture curl output
char *title_start, *title_end; // Pointers to start and end of <title> tag
// Run curl command and capture output
curl_output = popen("curl https://scrape-it.nl/", "r");
if (curl_output == NULL) {
printf("Failed to run curl command.n");
return 1;
}
// Read the output of curl into html buffer
fread(html, sizeof(char), MAX_HTML_SIZE, curl_output);
// Close the file pointer
pclose(curl_output);
// Find the start of first <title> tag
title_start = strstr(html, "<title>");
if (title_start == NULL) {
printf("No <title> tag found.n");
return 1;
}
// Move pointer to start of content within <title> tags
title_start += 7; // Move to the position after "<title>"
// Find the end of first <title> tag
title_end = strstr(title_start, "</title>");
if (title_end == NULL) {
printf("Invalid <title> tag.n");
return 1;
}
// Null-terminate the content within <title> tags
*title_end = '�';
// Print the content within first <title> tag
printf("Content within <title> tag: %sn", title_start);
return 0;
}
Deze code haalt de titel van een Scrape IT-website op. Het gebruikt een tool genaamd curl om de HTML-inhoud van de website op te halen. Vervolgens wordt de titel in de HTML-code gezocht en afgedrukt.
Output:
Scrapen van het web met C #
Code:
using System;
using HtmlAgilityPack;
namespace ScrapeItScrapingCSharp
{
internal class Program
{
static void Main(string[] args)
{
// Create HtmlWeb instance
HtmlWeb web = new HtmlWeb();
// Load website
HtmlDocument doc = web.Load("https://scrape-it.nl/");
// Get title node
HtmlNode titleNode = doc.DocumentNode.SelectSingleNode("//title");
// Check if title node exists
if (titleNode != null)
{
// Print title text
Console.WriteLine("Content within <title> tag: " + titleNode.InnerText);
}
else
{
// Print error message if title node is not found
Console.WriteLine("No <title> tag found.");
}
}
}
}
Deze code haalt de HTML-inhoud van een website op en maakt gebruik van de HtmlAgilityPack-bibliotheek in C#. Met deze mogelijkheden kunnen we eenvoudig het <title> element targeten met XPath en de tekst ophalen. Deze eenvoudige aanpak vereenvoudigt het parsen van HTML, waardoor het moeiteloos is om specifieke elementen van de website op te halen.
Output:
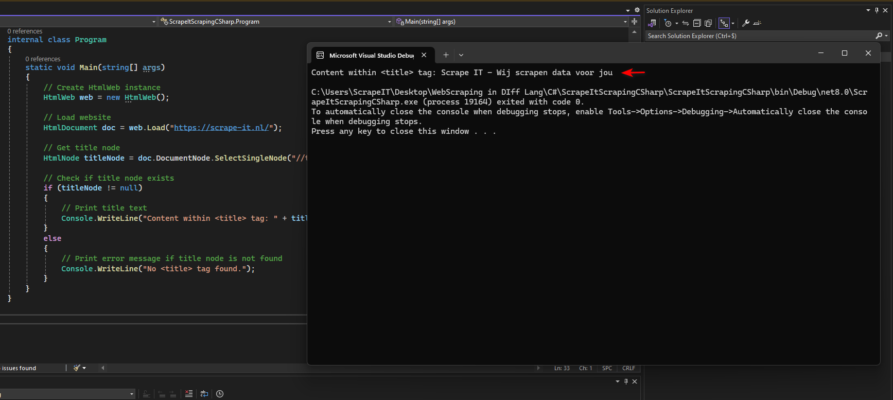
Web scraping met Java
Code:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class Main {
public static void main(String[] args) {
// URL of the website to scrape
String url = "https://scrape-it.nl/";
try {
// Connect to the website and get the HTML document
Document doc = Jsoup.connect(url).get();
// Get the title element
Element titleElement = doc.select("title").first();
// Check if the title element exists
if (titleElement != null) {
// Print the title text
System.out.println("Content within <title> tag: " + titleElement.text());
} else {
// Print error message if title element is not found
System.out.println("No <title> tag found.");
}
} catch (IOException e) {
// Print error message if connection fails
System.out.println("Failed to fetch HTML content: " + e.getMessage());
}
}
}
Deze Java-code haalt de HTML-inhoud van een website op en maakt gebruik van de Jsoup-bibliotheek. Jsoup vergemakkelijkt het parsen en navigeren van HTML en stelt ons in staat om eenvoudig het <title> element te targeten met CSS selector syntaxis. Door de tekst van het <title> element op te halen, verkrijgen we de titel van de website.
Output:
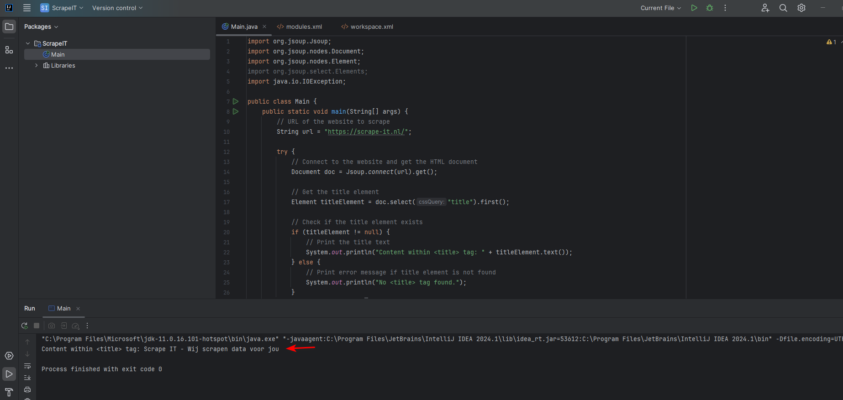
Web scraping met Javascript
Code:
// URL of the website to scrape
const url = 'https://scrape-it.nl/';
// Fetch HTML content
fetch(url)
.then(response => response.text())
.then(html => {
// Parse HTML content
const parser = new DOMParser();
const doc = parser.parseFromString(html, 'text/html');
// Get the title element
const titleElement = doc.querySelector('title');
// Check if the title element exists
if (titleElement) {
// Print the title text
console.log(`Content within <title> tag: ${titleElement.textContent}`);
} else {
// Print error message if title element is not found
console.log('No <title> tag found.');
}
})
.catch(error => {
// Print error message if fetching fails
console.error(`Failed to fetch HTML content: ${error}`);
});
Deze JavaScript-code haalt de HTML-inhoud van een website op met behulp van de native fetch API. Door gebruik te maken van de DOMParser-interface parseren we de HTML-inhoud en navigeren we door het document naar het <title> element. Zodra het <title> element is geïdentificeerd, extraheren we de tekst om de titel van de website te verkrijgen.
Output:
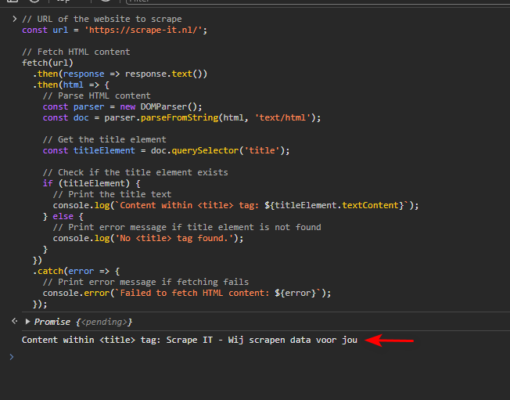
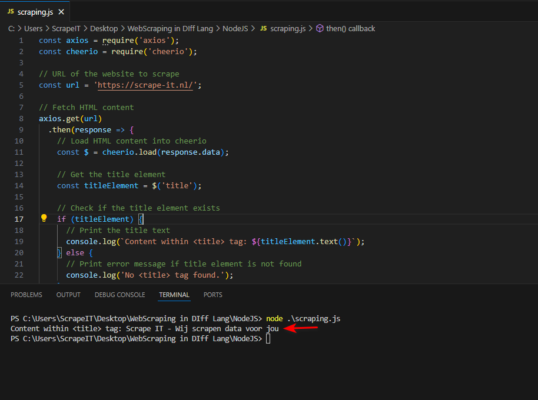
Scrapen van het web met NodeJS
Code:
const axios = require('axios');
const cheerio = require('cheerio');
// URL of the website to scrape
const url = 'https://scrape-it.nl/';
// Fetch HTML content
axios.get(url)
.then(response => {
// Load HTML content into cheerio
const $ = cheerio.load(response.data);
// Get the title element
const titleElement = $('title');
// Check if the title element exists
if (titleElement) {
// Print the title text
console.log(`Content within <title> tag: ${titleElement.text()}`);
} else {
// Print error message if title element is not found
console.log('No <title> tag found.');
}
})
.catch(error => {
// Print error message if fetching fails
console.error(`Failed to fetch HTML content: ${error}`);
});
Deze Node.js code haalt de HTML-inhoud van een website op met behulp van de axios bibliotheek, een populaire HTTP-client voor Node.js. Met behulp van de cheerio-bibliotheek laden we de HTML-inhoud in een virtuele DOM en gebruiken we jQuery-achtige syntaxis om de HTML-structuur te doorlopen en te manipuleren. Door ons te richten op het <title> element, extraheren we de tekst om de titel van de website op te halen
Output:
Wat als we web scraping willen uitvoeren met de eerste programmeertaal ooit?
Ik vroeg Google wat de eerste programmeertaal is en het antwoord was Fortran.
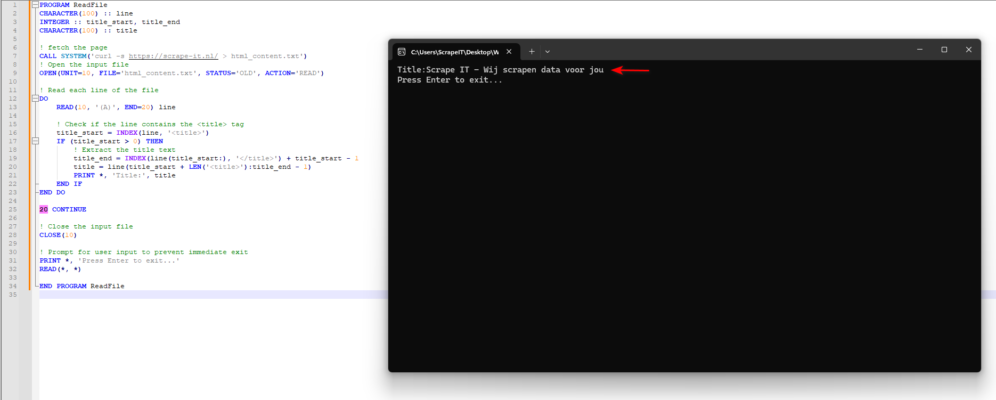
Scrapen van het web met Fortran
Code:
PROGRAM ReadFile
CHARACTER(100) :: line
INTEGER :: title_start, title_end
CHARACTER(100) :: title
! fetch the page
CALL SYSTEM('curl -s https://scrape-it.nl/ > html_content.txt')
! Open the input file
OPEN(UNIT=10, FILE='html_content.txt', STATUS='OLD', ACTION='READ')
! Read each line of the file
DO
READ(10, '(A)', END=20) line
! Check if the line contains the <title> tag
title_start = INDEX(line, '<title>')
IF (title_start > 0) THEN
! Extract the title text
title_end = INDEX(line(title_start:), '</title>') + title_start - 1
title = line(title_start + LEN('<title>'):title_end - 1)
PRINT *, 'Title:', title
END IF
END DO
20 CONTINUE
! Close the input file
CLOSE(10)
! Prompt for user input to prevent immediate exit
PRINT *, 'Press Enter to exit...'
READ(*, *)
END PROGRAM ReadFile
Deze Fortran-code haalt de HTML-inhoud van een website op met het commando curl en opent vervolgens het opgeslagen bestand (html_content.txt) om de inhoud te lezen. Het leest elke regel van het bestand, op zoek naar de
Output:
Tot slot van onze ontdekkingstocht hebben we in dit artikel de basisbeginselen van web scraping behandeld. Zie het als het kiezen van tools voor een project - of je nu de voorkeur geeft aan Python, C#, Java of zelfs Fortran, het gaat erom wat bij jouw stijl past. En hé, ik ben niet tegen Python - het is ook nog steeds leuk om met Python te coderen! Maar onthoud dat web scraping niet afhankelijk is van een specifieke taal. Dus kies je favoriet, duik erin en begin met het ontdekken van de schatten die verborgen liggen op het web!